

I used to spend hours manually transcribing interviews, rewinding audio clips over and over, just to catch every word. It was exhausting—until I discovered Whisper API.
Whisper API makes converting WAV files to text effortless, saving time and eliminating transcription headaches. Developed by OpenAI, this powerful speech-to-text tool leverages deep learning to accurately transcribe audio files, even in noisy environments. Whether you’re a journalist, researcher, or developer automating workflows, Whisper API transforms WAV audio into readable text with impressive accuracy.
But here’s the catch: setting it up and optimizing results isn’t always straightforward. In this guide, I’ll walk you through everything you need to know—from installation to best practices—so you can unlock the full potential of Whisper API for seamless transcription.
Download the Whisper AI Cheat Sheet
What is Whisper API
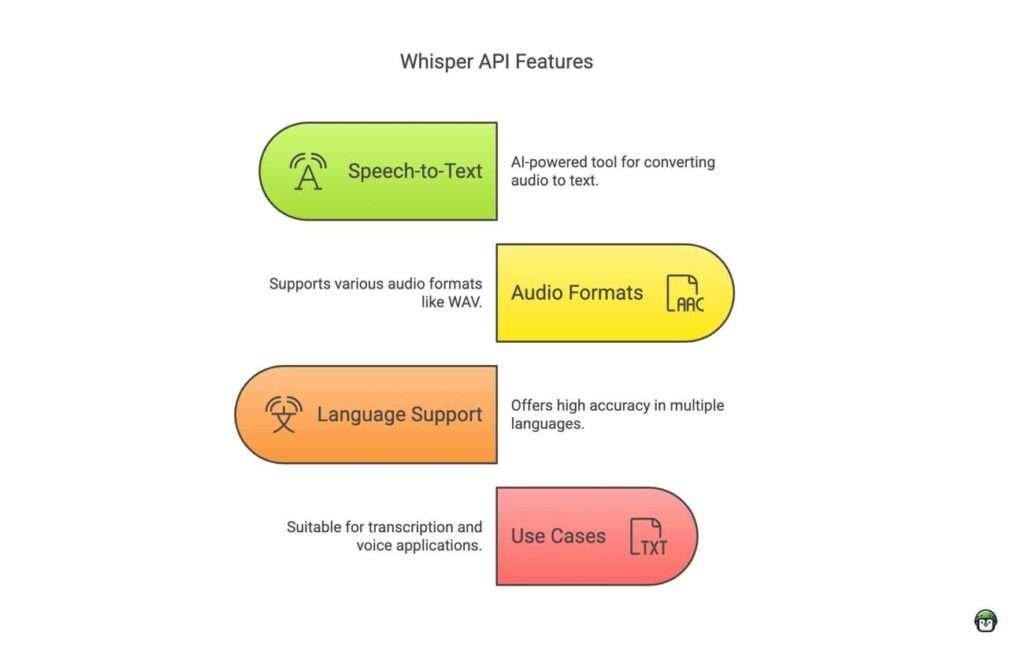
Whisper API is an open-source, AI-powered speech-to-text system developed by OpenAI. It enables automatic transcription of audio files, including WAV formats, into accurate, readable text. Unlike traditional speech recognition tools, Whisper API leverages deep learning models trained on a vast dataset of multilingual and multitask audio, making it highly effective even in noisy environments or with diverse accents.
Key Features of Whisper API:
- High Accuracy – Uses advanced AI models to produce precise transcriptions.
- Multilingual Support – Recognizes and transcribes multiple languages.
- Robust Against Background Noise – Performs well even with audio distortions.
- Flexible Integration – Can be used via an API for automation in applications.
- Open-Source – Available for free, aligning with the FOSS philosophy.
Whether you’re transcribing interviews, automating subtitles, or processing audio data for research, Whisper API provides a reliable and efficient solution for converting speech into text.
Prerequisites
Before we start, ensure you have the following:
- Python installed on your system
- Basic knowledge of Python programming
- Internet connection to download dependencies
· · ─ ·𖥸· ─ · ·
Installation and Dependencies
First, let’s install the necessary dependencies. We’ll need whisper and pydub for handling audio files. Install these using pip:
pip install openai-whisper pydubAdditionally, you might need ffmpeg to handle audio conversions. You can install it using:
Windows:
Download the executable from FFmpeg website and add it to your PATH.
macOS:
Use Homebrew with the command brew install ffmpeg.
brew install ffmpegLinux:
Use your package manager, e.g., sudo apt install ffmpeg for Debian-based systems.
sudo apt install ffmpeg· · ─ ·𖥸· ─ · ·
Converting WAV to Text Using Whisper API
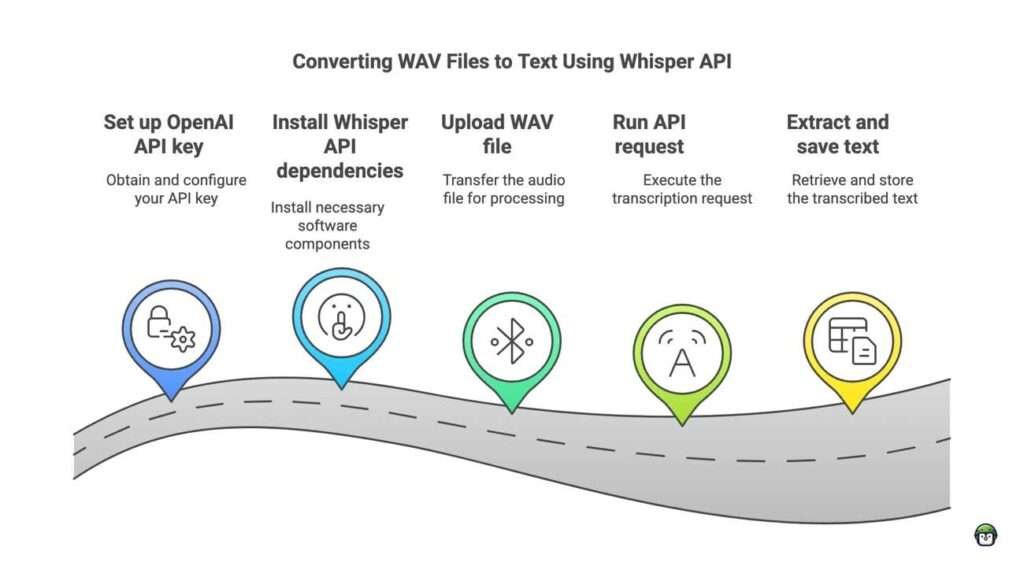
Here’s a simple Python script to convert a WAV file to text using the Whisper API:
import whisper
from pydub import AudioSegment
def convert_wav_to_text(wav_file_path, output_text_file):
# Load and prepare the audio file
audio = AudioSegment.from_wav(wav_file_path)
audio = audio.set_channels(1)
audio.export("temp.wav", format="wav")
# Load Whisper model and transcribe
model = whisper.load_model("base")
result = model.transcribe("temp.wav")
# Save transcription to file
with open(output_text_file, 'w') as f:
f.write(result['text'])
print(f"Transcribed text written to {output_text_file}")
# Usage example
convert_wav_to_text("your_audio_file.wav", "transcribed_text.txt")
· · ─ ·𖥸· ─ · ·
How Whisper API Works
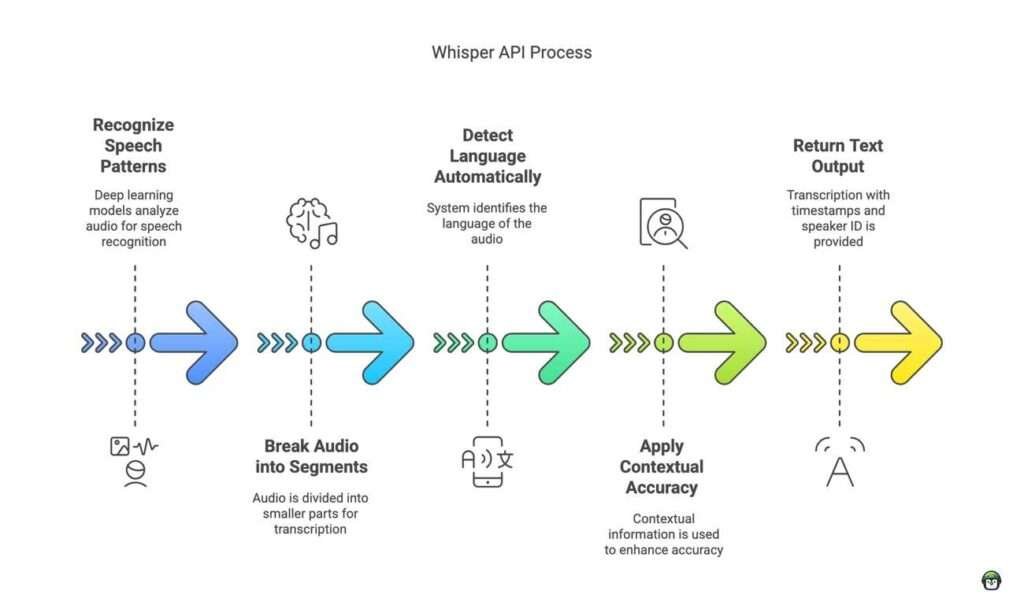
Whisper API leverages deep learning models to transcribe audio into text with remarkable accuracy. Its foundation is a neural network trained on vast amounts of spoken language data, enabling it to recognize speech patterns, different accents, and even background noise. Here’s a step-by-step breakdown of how it works:
1. Audio Input Processing
- The API accepts various audio formats, including WAV, MP3, and M4A.
- It normalizes the audio to enhance clarity and reduce distortions.
2. Speech Recognition Using AI Models
- Whisper API uses a transformer-based neural network to analyze the sound waves.
- It segments the audio into smaller chunks and processes them in parallel.
3. Language Detection and Transcription
- Automatically detects the spoken language in the audio.
- Converts speech into text using pre-trained AI models.
4. Context Understanding and Error Correction
- Uses natural language processing (NLP) to improve transcription accuracy.
- Corrects misinterpretations by analyzing context and grammar.
5. Output and Integration
- The transcribed text is returned in JSON format.
- Can be integrated into apps, bots, or research tools for automation.
With its powerful AI-driven approach, Whisper API provides developers and researchers with a reliable tool for speech-to-text conversion, making audio data more accessible and actionable.
· · ─ ·𖥸· ─ · ·
Use Cases
- Meeting Transcription – Record your meetings and use this script to transcribe them, making it easy to reference and share minutes.
- Podcast Transcription – Convert podcast episodes into text for creating show notes or blog posts.
- Voice Command Applications – Implement voice commands in your applications by transcribing spoken words to text and processing them accordingly.
- Accessibility – Provide transcripts for audio content, making it accessible to individuals with hearing impairments.
· · ─ ·𖥸· ─ · ·

· · ─ ·𖥸· ─ · ·
Unlock the Power of Whisper API Today
Transcribing audio manually is tedious, but Whisper API eliminates the hassle with its AI-powered accuracy and efficiency. Whether you’re a developer building voice-driven applications, a researcher analyzing interviews, or a journalist transcribing recordings, this tool simplifies speech-to-text conversion with just a few lines of code.
Don’t let valuable audio data go unutilized—harness Whisper API to convert WAV files and other formats into accurate, structured text effortlessly. Start integrating Whisper API into your workflow today and experience seamless, automated transcription.
Here’s sometihing that might interest you:
Leave a Reply